-
![thumbnail]()
-
Note sur les Policy IAM
December 12, 2016 at 12:59:10 PM GMT+1 - permalink -Une policy IAM est constituée de statement, ce sont des règles (des blocs de codes)
{
"Statement":[{
"Effect":"effect",
"Action":"action",
"Resource":"arn",
"Condition":{
"condition":{
"key":"value"
}
}
}
]
}Chaque règle dans sa forme la plus simple est composée de 3 choses :
Effect : allow ou deny
Action : quelle action concerne la règle
Resource : la resource concernée
Chaque service Amazon (EC2, ECR, etc...) expose une liste d'action, on peut trouver cette liste dans la doc (http://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_elements.html#Action)
Et chaque resource peut être identifiée par un arn (une manière simple de retrouver un ARN est d'afficher la resources dans l'interface web AWS, il y a souvent l'arn)
 -
https://links.infomee.fr/?3KOHAQ
-
https://links.infomee.fr/?3KOHAQ
-
Blog Stéphane Bortzmeyer: BCP 38, ne pas laisser des adresses IP usurpées sortir de son réseau
December 9, 2016 at 11:36:44 PM GMT+1 - permalink -J'avais eu les RFC sur ce sujet à commenter pendant le Master, souvenir ahah
-
http://www.bortzmeyer.org/bcp38.html
-
PrivateBin
December 9, 2016 at 4:00:18 PM GMT+1 - permalink -fork zerobin
via arnaudb
-
https://privatebin.net/
-
Note: inception
December 9, 2016 at 2:06:22 PM GMT+1 - permalink -I've edited my .vimrc to add fugitive plugin and commited it by using fugitive
-
https://links.infomee.fr/?4Ww4qQ
-
![thumbnail]()
-
Note: AWS Beanstalk et cron
December 9, 2016 at 11:13:10 AM GMT+1 - permalink -On peut avoir besoin de faire tourner un ou plusieurs cron dans un environnement Beanstalk composé de X instances
Etant donné que toute les instances sont configurées de la meme manière, si on rajoute le cron dans la config, il sera éxecuté sur toutes les instancesUne solution serait de determiner si on est le "runnner" ou non avant de lancer le cron
Pour que toutes les instances sachent qui est le runner, on peut imaginer un système comme celui ci :
- on interroge l'ELB avec les API pour avoir ses backends
- on trie cette liste de backend
- le runner est le premier de cette liste
- si notre ip est égale à celle du runner, on lance le cron
ça a l'avantage de fonctionner quel que soit le nombre d'instances et ne pas stocker un état (on utilise les infos de l'ELB)
Et si on ne veut pas faire tourner tous les crons sur le runner, on pourrait déterminer runnner1 runnner2 runner3 etc suivant l'ordre et faire tourner certains crons si on est runner1 ou bien runner2
-
https://links.infomee.fr/?fmh_YQ
-
Malcolm best of FR - YouTube
December 9, 2016 at 11:05:47 AM GMT+1 - permalink -Souvent mes journées au taf ressemblent à ça : je veux changer une ampoule, je finis sous la voiture
-
https://www.youtube.com/watch?v=NgzMWmVkn_4&feature=youtu.be&t=161
-
![thumbnail]()
-
Detecting File Moves & Renames with Rsync | Lincoln Loop
December 8, 2016 at 8:46:34 AM GMT+1 - permalink -Une méthode pour ne pas rsync des fichiers qui ont été déplacés dans la source
Et en commentaire une extension à la solution qui m'a l'air pas mal du tout
I use a derivative of this method, by creating a separate hard-links directory with md5-filenames. This gets rid of any duplicate files as well. Any files in this hard links directory with link count 1 are removed. Any files in the albums tree without the same inode to be found in the hard links tree are hard-linked into the hard links tree by using an MD5 of the file. Before I rsync I update the hard links dir, so when my wife decides to make a beautiful photobook and copies and moves lots of photos around, my ADSL doesn't get swamped when backing up my local photo store.
The same script also generates JPG files from Nikon image files (NEF).
This works both on FreeBSD/Linux/UNIX/etc as well as NTFS. Which is nice.
-
https://lincolnloop.com/blog/detecting-file-moves-renames-rsync/
-
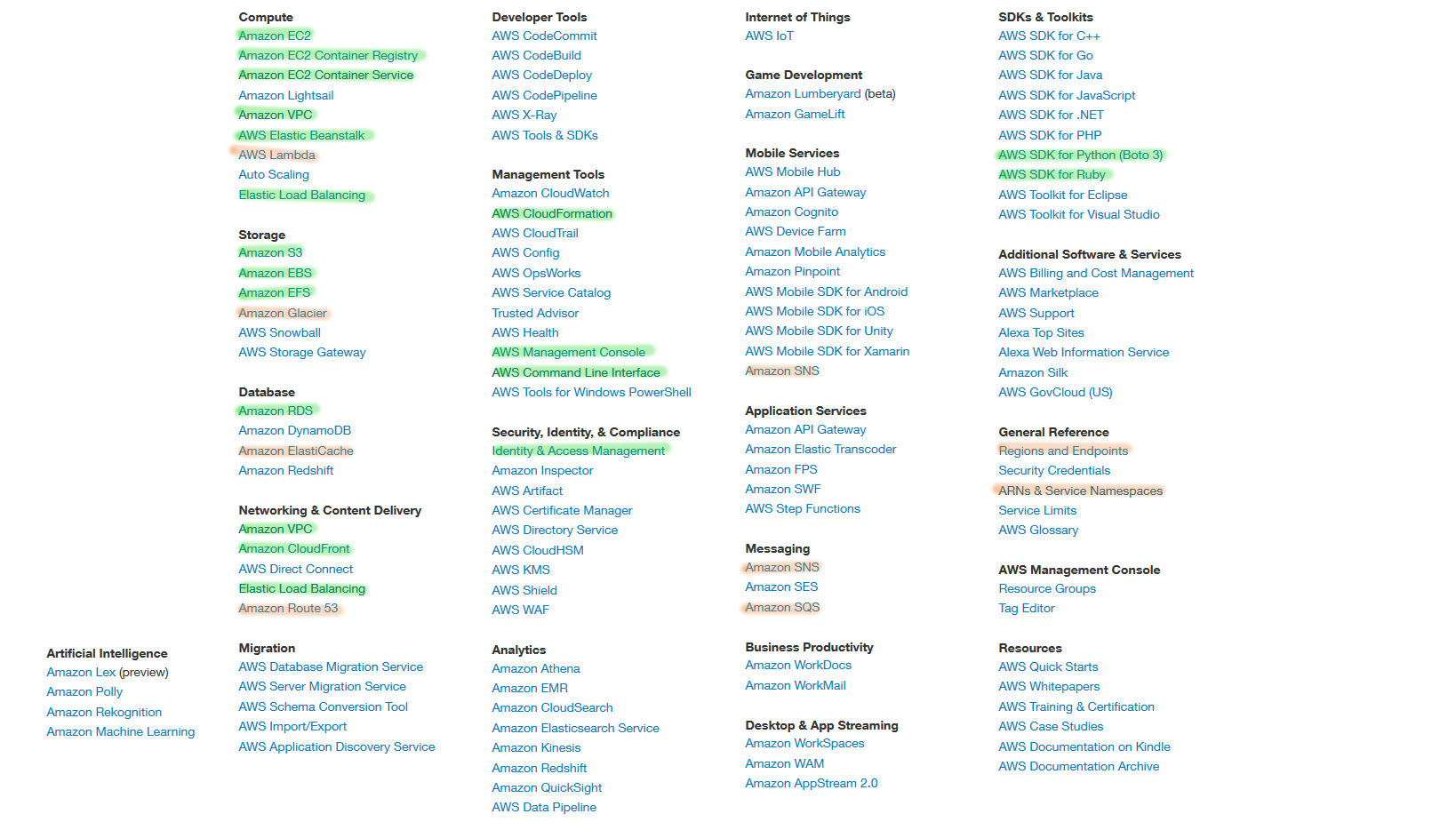
![thumbnail]() aws.png
aws.png
December 7, 2016 at 11:48:00 AM GMT+1 - permalink -Bientôt 3 mois que j'ai commencé avec AWS
En vert ce avec quoi j'ai pu bien jouer
En orange survolé
Et tout le resteCe qui me plait le plus : tout est automatisable soit avec des appels à l'api (SDK dans beaucoup de langage) donc en mode séquentiel, soit avec CloudFormation, une sorte de Configuration Management donc en mode declaratif
rdv dans 3 mois ;)
-
https://infomee.fr/vrac/aws.png
-
![thumbnail]() Solutions Architect—Associate Certification for AWS
Solutions Architect—Associate Certification for AWS
December 7, 2016 at 10:35:03 AM GMT+1 - permalink -online resources to prepare aws certifications
-
https://cloudacademy.com/learning-paths/solutions-architect-associate-aws-14/